By W. Patrick, Walters
May 25, 2026
Mapping the avoid-ome: a systematic open-science approach to predictive ADMET
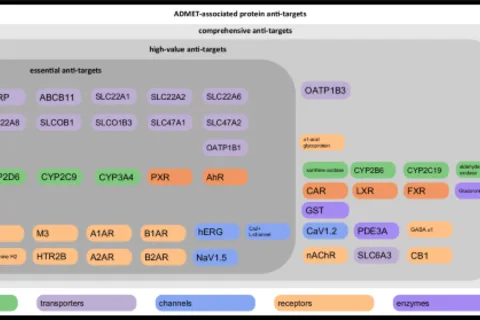
Over the last 20 years, the number of new drug modalities have multiplied quickly 1 . Despite this, the oldest modality, small molecules, still accounts for ~3/4 of drugs approved by the FDA over the last decade 2 , 3 . Small molecules continue to dominate and even flourish for three main reasons: (1) small molecules have inherent distribution advantages with potential to reach every organ, cell, and organelle in the body; (2) modern engineering principles enable us to scale production and deliver them economically worldwide in predictable ways; and (3) our increased understanding of how small molecules engage proteins has led to a renaissance of new small molecule targeting modalities, such as covalent modifiers, correctors, allosteric modulators, induced proximity, degraders, and RNA/splicing/PPI/condensate modulators. However, the ability to modulate all functions in the body also belies the challenges of dialing in unpredictable pharmacokinetic and safety properties. Drug discoverers must optimize for high potency at the target while avoiding interactions with related or idiosyncratic off-target proteins. The discovery process must also navigate problematic ADMET (Absorption, Distribution, Metabolism, Excretion, Toxicity) issues that would cause a candidate to fail in preclinical development or, worse yet, clinical trials. Thus, drug design requires a multiparameter optimization process that balances many different factors 1 , 3 . While every new target and related off-targets are unique to every program, the ADMET properties are shared, and thus, the focused development of predictive tools would broadly enable small-molecule drug discovery. Over the last 40 years, we’ve come to understand ADMET issues are largely driven by a finite set of proteins and physicochemical properties that can be measured in individual assays. While pharmacophore models and heuristics have been created to tackle specific liabilities, the field has not taken a systematic approach to understanding and correcting ADMET liabilities. Additionally, structure-based design, which has become a key part of modern drug discovery, is seldom used beyond primary target binding. Despite significant progress in structure-based design and affinity prediction, ADMET properties remain the main reason for failure in drug discovery. More than 90% of molecules created during discovery fail to meet basic ADME standards 3 , 4 , 5 . Additionally, it is estimated that about 20% of drug candidates fail in preclinical toxicity tests, and around 30% of clinical failures are due to unexpected ADMET problems 3 , 4 , 5 . Traditional methods that focus mainly on bulk molecular properties 6 , such as logP, solubility, or hydrogen bond donor counts, offer only vague guidance because they lack insight into the atomic-level interactions between drugs and the body’s complex systems. Several machine learning (ML) representations 7 , including chemical fingerprints, molecular graphs, 3D geometry-based models, and protein language models, are already aiding ADMET predictions. However, two key challenges hinder breakthroughs in predictive ADMET: the data remain extremely limited, and most models lack the atomistic detail needed for mechanistic understanding. What is missing from this perspective is a systematic, detailed understanding of the “Avoid-ome”: the broad set of proteins that influence the ADME and toxicity properties of all drug molecules 8 . By focusing the tools of modern structure-based drug design on the Avoid-ome, drug discovery practice could be transformed. Defining the avoid-ome The Avoid-ome consists of enzymes, transporters, receptors, and channels that determine whether a compound reaches its intended target or fails due to off-target binding 9 , 10 . These include metabolic enzymes like cytochrome P450s (CYPs) 11 , aldehyde oxidase 12 , UDP-glucuronosyltransferases (UGTs) 13 , and glutathione S-transferases (GSTs) 14 ; transporters from the ABC 15 and SLC 16 families; plasma proteins such as serum albumin 17 ; xenobiotic sensors like the pregnane X receptor (PXR) 18 and constitutive androstane receptor (CAR) 19 ; and common toxicity drivers such as the hERG potassium channel 20 , the voltage-gated sodium channel NaV1.5 21 , and L-type calcium channels 22 . The primary Avoid-ome targets can be divided into four groups: absorption and excretion (A/E), distribution (D), metabolism (M), and toxicity (T) (Fig. 1 ). Fig. 1: The set of protein anti-targets that comprise the Avoid-ome. The alternative text for this image may have been generated using AI. Full size image These anti-targets can be categorized horizontally as essential, high-value, or comprehensive anti-targets. The colors in the plot further illustrate the mechanistic classes associated with each target. Importantly, the Avoid-ome is a finite set: although thousands of proteins exist in the human proteome, only on the order of 50-100 proteins occur with high frequency as mediating ADMET properties; considering less common situations, perhaps a few hundred proteins in total are responsible for the preponderance of the ADMET challenges faced by discovery teams. While this initial target list is not definitive and is intended to start a conversation among the community, this bounded scope makes the Avoid-ome problem tractable if we can systematically generate and share the correct data. Some Avoid-ome proteins are exploited therapeutically, such as P-gp in cancer 23 or SGLT2 in diabetes 24 . However, in most cases, drugs must be engineered to avoid them. Avoid-ome proteins are therefore not generally “targets” (the intended binding partner of a drug) or “off-targets” (proteins related to the intended binding partner). Instead, they are “anti-targets” (proteins that must be considered as potential confounders in most drug development projects). Consider an example of a kinase inhibitor to illustrate the distinctions between targets, off-targets, and anti-targets (Fig. 2 ). Cyclin-dependent kinase 2 (CDK2) 25 is a vital serine/threonine protein kinase that plays a crucial role in regulating the eukaryotic cell cycle, particularly during the transition from the G1 phase to DNA synthesis (S phase). Abnormal (uncontrolled) activity of the CDK2/Cyclin E complex is commonly observed in many human cancers. This leads to increased cell proliferation and genomic instability, making CDK2 an important target for anti-cancer therapies. The primary off-targets of CDK2 inhibitors are usually other members of the CDK family because of their high similarity in ATP-binding sites. Ensuring off-target selectivity during the design of CDK2 inhibitors is essential for the safety and effectiveness of the drug. Lack of selectivity was a major reason why first-generation CDK2 inhibitors failed in early clinical trials. Additionally, anti-target selectivity against proteins such as CYPs and PXR is vital to prevent drug interactions, and avoiding the hERG ion channel is crucial in designing CDK2 inhibitors to prevent serious cardiac side effects. As the focus shifts from targets to off-targets and anti-targets, the number of binding sites and interactions to consider increases dramatically. The task of optimization is further complicated by the promiscuity of anti-targets, which have evolved to recognize a wide range of xenobiotics. This highlights the central challenge: success requires simultaneous optimization against every anti-target, yet systematic data on these interactions are almost entirely lacking. Fig. 2: The distinction between targets, off-targets, and avoid-ome anti-targets. The alternative text for this image may have been generated using AI. Full size image While on-target optimization usually involves interactions at a single binding site, considering off-targets introduces selectivity challenges as the major interactions driving affinity are likely conserved. Structures of an inhibitor bound in the active sites of CDK2 (PDB:4KD1) and CDK1 (PDB: 6GU6) are highly similar, with many interactions, such as the hinge binding motif highlighted by dashed lines, nearly identical. In contrast, structure predictions of the same compound bound to anti-targets such as hERG, CYP3A4, and PXR reveal a great diversity in hydrophobic and hydrogen bond interactions within the membrane protein hERG, the heme-containing binding pocket of CYP3A4, and the fully buried ligand binding site of PXR. The case for openADMET How can we enable breakthroughs in ADMET modeling? Deep learning approaches crave data 26 , yet very little is known about the ADMET properties of drug-like compounds. Publicly accessible databases, such as ChEMBL 27 and the Therapeutics Data Commons 28 , include ADMET datasets compiled from the literature. However, this data has often been extracted from dozens of papers, each using different experimental procedures. As highlighted in a recent paper by Landrum and Riniker 29 , reported values in the literature are rarely consistent. The pharmaceutical industry could be a valuable source of ADMET data. In fact, important ADMET datasets are stored within pharmaceutical companies, and making this data publicly available would be beneficial. However, even full access to this data would still be insufficient. To gain a comprehensive understanding, we need to systematically examine the interactions between the most common Avoid-ome targets and diverse sets of ligands that broadly cover chemical space. The convergence of multiple factors has created an opportunity to systematically improve ADMET optimization. Recent advances in structural biology have enabled higher-throughput data collection and will allow us to study the structures of Avoid-ome proteins on a much larger scale. Additionally, advances in mass spectrometry have made data collection more cost-effective. Finally, the availability of open-source machine learning models has provided the ability to link structural and assay data to develop new strategies for compound optimization. OpenADMET ( http://openadmet.org ), a major international open‐science initiative initially funded by ARPA-H and the Gates Foundation, aims to leverage these scientific advances and address the ADMET data gap by developing pre-competitive, open datasets covering metabolism, transport, distribution, and toxicity. The OpenADMET consortium is a collaborative effort between the University of California, San Francisco (UCSF), Octant, and the Open Molecular Software Foundation (OMSF). We are creating platforms to make synthesizing compounds, conducting measurements, and learning from data cheaper and higher throughput. These large, openly accessible datasets will serve as a shared resource for the global research community. Our approach also leverages high-throughput structural biology to support model interpretability, identify outliers and cryptic binding modes, and ensure models are grounded in mechanistic, atomistic insights (Fig. 3 ). Fig. 3: This schematic illustrates the collaborative pipeline employed by OpenADMET. The alternative text for this image may have been generated using AI. Full size image While the process typically begins with initial HTS screening, it also allows for focused entry points via protein-ligand crystal structures to jump-start modeling or fragment screens to guide expansion. Integrated structural biology (X-ray/cryoEM) and functional data drive a continuous loop of model refinement and analog synthesis, shifting the focus from initial hits to exploring SAR (structure-activity relationship) around active compounds and resolving outliers. In addition to the elements described above, genetic variation-aware predictions will be needed to realize the potential of pharmacogenomic analyses. We are integrating data such as VAMPseq 30 protein expression levels and atomistic modeling of how variants alter ADMET risk by changing interactions between the compound and the anti-target. Pre-clinical species translation is another essential component, requiring structural models that explain why compounds behave differently across rats, dogs, monkeys, and humans 31 . Another often-discussed alternative approach to feeding the data needs of machine learning approaches in ADMET is federated learning 32 , where models are trained behind a firewall that can observe data from companies without sharing the underlying molecular identities. While appealing in principle, such solutions tend to reinforce limitations: they remain confined to local chemical space, they struggle to generalize, and they rarely deliver the mechanistic clarity required to address Avoid-ome proteins. By contrast, active learning 33 over diverse chemical space creates the conditions for truly generalizable models and deeper insights that can benefit the entire community. Freed from the constraints of having to generate molecules to “avoid” anti-targets, in OpenADMET we can synthesize and test compounds that are most informative for building predictive models. This close link between experiment and computation lets us ask, “which experiments will enable us to build the best model?” Another key element of OpenADMET is the creation of blind community challenges to benchmark models using unreleased data, thereby promoting rigorous evaluation and continuous improvement. Collectively, these strategies will generate the data necessary for improved predictions and establish a framework for integrating functional data on specific anti-targets with bulk property assays, such as stability in the presence of liver microsomes, to connect mechanistic understanding with applied pharmacology. Assays The OpenADMET initiative requires diverse assays across many anti-targets: biochemical assays for metabolism and transport, electrophysiology for ion channels, binding assays for plasma proteins, and transcriptional readouts for xenobiotic sensors (Fig. 4 ). A key goal is to modernize these assays, making them cheaper, more scalable, and more translatable. We begin by characterizing individual Avoid-ome targets to understand the mechanistic basis of ADMET liabilities before progressing to integrative assays like microsomal stability. Fig. 4: The assays used to drive the current OpenADMET efforts. The alternative text for this image may have been generated using AI. Full size image Additional assays will be added as new targets are introduced. For metabolism and biochemical assays, we leverage scaled mass spectrometry 34 to enhance throughput and reduce costs. For cellular assays, we employ synthetic biology 35 to engineer high signal-to-noise genetic reporters and routinely include counter-assays with target knockouts to mitigate PAINS effects. Our goal is affordable, quantitative, scalable methods applicable to both purified compounds and those from next-generation direct-to-biology platforms. Currently, we evaluate CYP reactivity for thousands of compounds at <$0.40 per compound using an Echo-MS+ ZenoTOF 7600 system.
Source: Nature